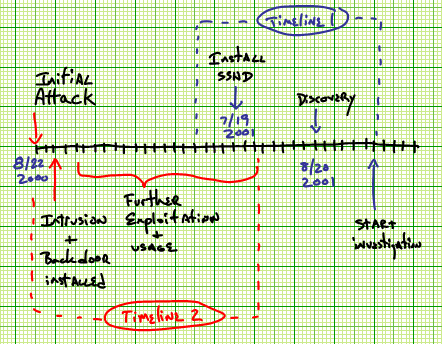
Figure 2.1: A full timeline of the Barney incident. Timeline one is mostly covered in section 2.5, while timeline two, further in the past, is discussed in this section.
In this chapter we'll introduce some basic methods of how to gather and interpret time data from the network and individual hosts - essentially constructing little time machines. While individual events might be interesting when considered in isolation, their sequence in time gives valuable context that may change their meaning. For instance, new programs are installed on a regular basis, but if one was introduced right after a computer was broken into it takes on new meaning.
While we deliberate over networking data and events in this particular chapter, throughout the book we'll be focusing mostly on information taken from individual systems. After all, the sheer volume easily captured from network taps is both the investigator's best friend and worst enemy - sometimes you can have it all, but what do you with it all? We will start off the chapter following a real incident to show how network data and host data can complement each other. We then move to show three unusual venues where time information can be found and analyzed - the raw disk, the combination of process memory and the network, and finally in the journal part of file systems.
There was trouble on the net. On August 20th of 2001, Barney, a harmless Linux computer previously used as a group's multimedia juke box, was found to have an ssh daemon (a program that enables encrypted network logins) listening for connections on a very strange TCP port. When no one confessed to installing the program it seemed clear that Barney had been compromised.
In a rush to help the situation, Barney's administrators created a backup of all the directories that appeared to contain suspicious files. An alert was then sent to the corporate computer security staff. It took three days, but finally the security team quarantined the computer, The Coroner's Toolkit (TCT) was unpacked (see appendix A for more on this software), the suspect disk drive examined, and a story started to unfold. The team knew what had happened, but wanted to know when and, if possible, why, it did.
At times knowing when something happened is more valuable than knowing what took place. Throughout this book we'll be focusing on techniques to either find or use time related data. There are two ways to get time data - by observing activity directly, and by observing the secondary effects an action has on its environment. In this section we'll focus on the latter.
One of the simplest things to understand and use in an investigation are MACtimes. MACtimes are not the McDonald's version of a time zone - it's simply a shorthand way to refer to the three time attributes - mtime, atime, and ctime - that are attached to any file or directory in UNIX, NT, and other file systems 1.
Footnote 1: Microsoft's file systems have four similar times - ChangeTime, CreationTime, LastAccessTime, and LastWriteTime [MSDN, 2004]. Linux also has the dtime attribute which is set when a file or directory has been deleted. In particular this doesn't affect files in the visible file system, only deleted files. We'll discuss more about how the file system keeps track of all this information in the chapter 3, "File System Basics".
Atime refers to the last time the file or directory was accessed. Mtimes, in contrast, are changed by modifying a file's contents. The ctime attribute keeps track of when the content or meta information about the file has changed - the owner, group, file permission, etc. Ctime may also be used as an approximation of when a file was deleted.
For all of these attributes, however, it is crucial to note the word "last" - MACtimes only keep track of the last time a file is disturbed; once it has been changed historical MACtime data is impossible to uncover 2.
Footnote 2: At least, most of the time. Journaling file systems can reveal recent history that would otherwise be lost in the system - for more see Section 2.8 "MACtimes in journaling file systems."
While on UNIX systems these times may be viewed by the humble ls command (see the ls man page for more details) and on NTFS by various 3rd party tools. In real situations, however, it's often easier to use TCT's mactime tool or to simply use the lstat() system call (which mactime itself uses) as evidenced by this simple Perl code fragment 3:
($dev, $inode, $mode, $nlink, $uid, $gid, $rdev, $size, $atime, $mtime, $ctime, $blksize, $blocks) = lstat($filename); print "$filename (MAC): $mtime,$atime,$ctime\n";
Footnote 3: MACtimes returned by the Perl lstat() function call are displayed as the number of seconds since January 1st, 1970, 00:00:00 UTC. NTFS keeps file times in 100 nanosecond chunks since Jan 1st, 1601; thankfully Perl converts this for you.
If you've never looked at MACtimes before it can be surprising how useful they can be; listing 2.1 shows a bit of what the security team found when Barney was investigated:
Jul 19 2001
time size MAC permissions owner file name
---- ---- --- ---------- ----- ---------
16:47:47 655360 m.. -rw-r--r-- root /usr/man/.s/sshdlinux.tar
16:48:13 655360 ..c -rw-r--r-- root /usr/man/.s/sshdlinux.tar
16:48:16 395 ..c -rwxrw-r-- 2002 /usr/man/.s/ssh.sh
880 ..c -rw-r--r-- 2002 /usr/man/.s/ssh_config
537 ..c -rw------- 2002 /usr/man/.s/ssh_host_key
341 ..c -rw-r--r-- 2002 /usr/man/.s/ssh_host_key.pub
16:48:20 1024 m.c drwxr-xr-x root /usr/man/.s
16:51:31 1024 m.c drwxr-xr-x root /home
1422 m.c -rw-r--r-- sue /home/sue/.Xdefaults
24 m.c -rw-r--r-- sue /home/sue/.bash_logout
230 m.c -rw-r--r-- sue /home/sue/.bash_profile
124 m.c -rw-r--r-- sue /home/sue/.bashrc
16:57:57 1024 m.c drwx------ sue /home/sue
9 m.c -rw------- sue /home/sue/.bash_history
Listing 2.1. Slightly edited mactime program output from Barney.
That this looks very similar to UNIX's ls -l output is no coincidence; the big difference here is the inclusion of the "MAC" column. This shows which of the three file time attributes (mtime, atime, and ctime) correspond to the dates and times in the first column.
This output shows that on July 19th, just before 5 PM, a user with root privileges created and unpacked a tar file (a popular UNIX file archive format) with a file name suspiciously looking like it contained a replacement for ssh. The file itself was in an even more suspicious location (you might as well use "Kilroy was here" as a directory name.) Finally, soon after the file creation user "sue" logged off.
You might have noticed that there were no atimes listed in the MACtime output. This is because the "helpful" administrator who copied all the files for safekeeping also destroyed a wide variety of evidence at the same moment. Backing up files before gathering other evidence was a very poor idea because it runs against the Order of Volatility (also known as the OOV - see appendix B for a more thorough discussion.) The OOV says that more ephemeral data should be harvested before more stable data, and in this case reading (or copying) a file will change the atime attribute to the time the file was read (note also that when a program is run the atime of the executable file will change, because the contents of the executable file must be read before execution.) Directories also have atimes - when you access a directory's contents the atime will be updated as well4.
Footnote 4: Many systems allow you to totally disable atime updates, which is something that one needs to be aware of when examining time stamp information. When investigating a system, turning off atimes can also be useful to avoid destroying atime information when it is not possible to mount a disk read-only.
We'll be returning to MACtimes throughout the book. While not as comprehensive as network data, they have the advantage that they may be gathered after an incident - indeed, long after, as we'll see in chapter 7, "Persistence of deleted file information". However, as useful as they can be for discovering what happened after the fact, MACtimes are not without problems. Collecting and analyzing them must be done with caution, as they are extremely ephemeral - a stiff electronic breeze can destroy any hope of recovering them. We saw how a well-intentioned user who simply backed up some files destroyed evidence by resetting the file access times.
While lstat()'ing a file does not change the MACtimes, opening a directory for reading will change the atime, so you must be certain to lstat() directories before opening them and examining their contents. Be cautious if using GUI-based file system management tools - many of these change the atime even when only listing files, as they read the file to figure out what icon should be displayed in the file listing. Digital hashes of file content are very useful and commonly used tool for a variety of forensic or administrative purposes, but must be done after the lstat() because reading a file changes the atime of that file.
If doing a serious investigation you'll ideally want to work from a duplicate of the media rather than using the original data. Failing that, mount the media read-only or at the very least turn off atime updates so that you don't inadvertently destroy or alter the data and come up with incorrect conclusions.
MACtimes most obvious shortcoming is that they only report on the last time a file has been disturbed and hence have no way of reporting on the historical activity of a file or directory. A program could run a thousand times and you'd only see evidence of a single occurrence. Another limitation is that MACtimes only show you the result of an action - not who did it.
MACtimes also degrade over time, displaying a sort of digital Alzheimer's. As the activity goes further back in the past you're fighting a losing battle. MACtimes are less useful on busy multi-user systems, because user activity becomes difficult to distinguish from intruder activity. MACtimes also don't help much when normal system activity resembles the kind of trouble that you wish to investigate.
Finally, MACtimes are easily forged. UNIX systems have the touch command that can change atimes and mtimes. Both Microsoft's NTFS and UNIX file systems can also use the utime() system call to change those two times, as this simple Perl fragment demonstrates:
$change_to = time(); # set to current time utime($change_to, $change_to, $file); # atime, mtime, filename
Ctimes are more difficult to change on UNIX systems because the ctime value is always taken from the system clock (NT provides the SetFileTime() system call that can be used to change all three times at once), but if an intruder has privileged user access they can reset the system clock and then change the ctime, or alternately bypass the file system and write the time directly to the disk. (we'll be talking more about this in section 3.9, "I've got you under my skin - delving under the file system".) Changing the system clock can cause other warning flags to sound, however - most systems don't like time going backwards or hopping around, and log files or other signs might tip off such activity.
According to legend [WIKI, 2004] some 2300 years ago Ptolemy III gave the order that all ships stopping at Alexandria under the watch of its great lighthouse were to be searched for books. All found were commandeered and copied; the duplicates were returned to the ship masters and the originals put into the Library of Alexandria. This capturing of information from ships passing by this ancient hub might be viewed as an early version of network packet capturing.
Modern network instrumentation is significantly easier to implement, and can be accomplished with network sniffing software, preferably on a dedicated host, and ideally with the network transmit wire physically severed. Perhaps the biggest benefit of network vs. host instrumentation is the ease in which the former can be accomplished - for instance, while it can require specialized software to capture keystroke or log activity at the host level, it's fairly easy to record keystrokes or the content of sessions at the network level.
Due to the volume of traffic, however, sites that monitor the network typically don't - can't - keep all the raw network data. Unlike, say, a honeypot or other controlled experiments, in the real world networks can generating staggering amounts of network traffic. For example Ohio State University, a large Midwestern college, currently generates about 300 gigabytes of Internet traffic an hour, enough to fill the largest of currently available hard drives ([Romig, 2004]). And with disks and data traffic continuing to grow at proportional rates ([Coffman, 2002]) this seems unlikely to change soon.
So instead of keeping raw data it is more common to summarize it as connection logs and statistics. No matter what method is used, however, preparing for disaster on the network level isn't important - it's mandatory. Networks are transport, not storage elements, so all data must be captured and stored in real time, or it will be lost forever. And while we would be among the last people to say that being prepared isn't a good idea, the sad truth is that most people aren't. This is the primary reason that we generally don't discuss networks in this book and focus instead on incidents in a post-mortem fashion on individual hosts.
Fortunately the corporate security staff had the foresight to have Argus (the network Audit Record Generation and Utilization System [Argus, 2004]) in place before the Barney incident we discussed earlier. Argus is software that reports on the network status and traffic that it listens to. The security team had been running Argus for a couple of years and had kept all the logs since they had started using the tool.
There were two things to look for - connections to the rogue ssh daemon (the port the program was listening to, TCP 33332, was unusual enough that it could be readily spotted even in large quantities of data; ironically if the intruder had simply placed it on ssh's normal port, it might have never been noticed) and a file transfer that might have placed the tar file onto Barney.
In this example Barney's IP address was 192.168.0.1 and the intruder came from 10.0.0.1. Finding the first session to the new ssh daemon was easy - it lasted 17 minutes, as seen by this slightly edited Argus output. Argus appends the port number to the IP address, and the "sSEfC" status flags indicate a complete TCP connection:
Jul 19 2001 start end proto source destination status ===================================================================== 16:30:47-16:47:16 tcp 10.0.0.1.1023 192.168.0.1.33332 sSEfC
Using that information it was simple to spot further connections and further track the incident. Just prior to the ssh connection the intruder entered from a second system and downloaded something to Barney with FTP (an FTP server uses TCP ports 20 and 21 to send data and receive commands.) from 10.0.1.1. This is quite possibly the ssh tar file that was downloaded earlier.
Jul 19 2001 16:28:34-16:29:36 tcp 192.168.0.1.1466 10.0.1.1.21 sSEfC 16:29:30-16:29:36 tcp 10.0.1.1.20 192.168.0.1.1467 sSEfC 16:30:47-16:47:16 tcp 10.0.0.1.1023 192.168.0.1.33332 sSEfC
Comparing the various sources of data revealed that the time on the Argus system and Barney's differed by some 17 minutes (purely coincidental to the duration of the initial ssh connection). Clock skews such as this are very common and can provide endless amounts of frustration when trying to correlate evidence from different sources.
If we scan the Argus logs further back we see the computer at 10.0.0.1 scanning the network for back doors on TCP port 110 (the POP3 mail service) and TCP port 21 (the ftp port.) We note that all the connections are from TCP source port 44445 - presumably such an unusual occurrence is not merely a coincidence. A connection lasting four and a half minutes to ftp suggests that there might have been a back door previously installed on Barney (the "sR" status flags mean a connection has been refused):
Jul 19 2001 16:25:32 tcp 10.0.0.1.44445 192.168.1.1.110 s 16:25:49 tcp 10.0.0.1.44445 192.168.0.1.110 sR 16:25:53-16:30:26 tcp 10.0.0.1.44445 192.168.0.1.21 sSEfR
At times Argus will miss a packet or connections will not gracefully terminate, so you'll see lack of acknowledgments and errant packets (such as the single initial request and the longer connection without the "C" indicating a completed connection.)
The unusual port numbers used by the attackers warranted additional searching, and certainly finding additional connections from TCP port 44445 was easy enough. Not only did we find the above traffic but another suspicious trail involving the same Barney machine, starting almost a year earlier - August 22, 2000. Barney was apparently compromised through the name daemon port (TCP port 53) by what was probably a server vulnerability.
Aug 21-22 2000 23:59:55-00:29:48 tcp 10.0.3.1.1882 192.168.0.1.53 sSEfR Aug 22 2000 00:08:32-00:09:04 tcp 192.168.0.1.1027 10.0.2.1.21 sSEfC 00:08:42-00:09:04 tcp 10.0.2.1.20 192.168.0.1.1028 sSEfC 00:11:08-00:13:26 tcp 192.168.0.1.1029 10.0.2.1.21 sSEfC 00:12:07-00:12:13 tcp 10.0.2.1.20 192.168.0.1.1030 sSEfC 00:13:38-00:13:35 tcp 10.0.2.1.44445 192.168.0.1.21 sSEfR
Barney's DNS server on port 53 was initially broken into from 10.0.3.1; this session extends over the entire time slice shown here. The intruder then uses ftp to pull a set of tools from another compromised system (10.0.2.1), and then finally tries out the newly installed backdoor using the TCP source port 44445. When the MACtime evidence was reexamined for activity during this time frame many signs of the first break-in were now found - knowing there is a problem makes finding things much, much easier! The case was finally closed after all the holes were patched.
Of course all the forensic data was there all along - they could have found all of this immediately after the initial break-in by simply looking at Argus logs or MACtime output. Alas, that's not how it usually works! In this case there was simply too much data to look at on an ongoing basis. It was only having some initial idea of where to look or what to look for that made the analysis possible. We'll revisit this idea again and again, but the detection of events is often much harder than analyzing them once you know something is amiss.
So what was discovered? Barney was broken into almost a year ago, and a crude back door was put in place. The intruder apparently wanted a better user experience, and installed ssh - thinking, perhaps, that the encrypted traffic might hide their tracks better. If this hadn't been done the intrusions might have never been found. Figure 2.1 is an overall timeline for the incident.
Figure 2.1: A full timeline of the Barney incident. Timeline one is mostly covered in section 2.5, while timeline two, further in the past, is discussed in this section.
Individual host data is fairly untrustworthy for a variety of reasons. The primary reasons are that it is exposed to the digital elements and attackers. It will erode over time by normal system behavior, and may also additionally modified by miscreants. Network data, on the other hand, has the potential of much higher fidelity, especially if steps have been taken to protect it and others don't know that it exists or where it is. It should be noted that even if you could capture all the traffic that flows through a network, interloper activity could still be undetectable or indecipherable due to encryption, covert channels, connectionless traffic, use of back doors hidden in legitimate protocol traffic (HTTP, SMTP, and so on), incorrect, broken, or fragmented network packets, and a host of other issues (see [Ptacek, 1998] for more).
However, even if the network data is encrypted traffic analysis can still be very useful, especially when combined with other types of information as shown in this chapter.
Some of the more interesting - but difficult to capture - wellsprings of time reside in the dark corners of the system. While there is no single way to access these, the many places such as kernel and process memory, unallocated disk space, removed files, swap files, peripherals, and others will often have a time stamp here, an audit record there, etc.
This type of time data is some of the most pernicious, undependable, and difficult for black hats and white hats alike to use, destroy, or even know about. Ignoring such data, however, should only be done at your peril. Barring a complete wipe of the system there is essentially no way that anyone can ever be certain that this data isn't still out there... somewhere. Based almost completely on undocumented and unpredictable locations and processes this information is both very interesting and very frustrating to work with, but text-based records in particular can be of use even if the data is incomplete or partially obliterated.
Besides, who needs file names to find data? We give labels to files only to make them easier to use and manipulate, and they have nothing to do with the content within. It's actually quite simple to view the data on the disk or in memory by simply looking outside of the box, at the raw bits. A text pager that can handle binary data can simply look at the raw data - for instance, less can be used to look at the physical memory of many UNIX systems:
solaris # less -f /dev/mem
Trying to find what you want from any system of significant size, however, can be a Herculean - but at times unavoidable - task. The hardest part of working with data is often not merely collecting it, but winnowing out the useless data. Raw memory can be particularly difficult because some of the most interesting data is stored in compact binary data representations that are almost impossible to decipher, since all context on what wrote it or why it is there has been lost (although see chapter 8, "Beyond Processes", for more.)
However even raw and hard to process data may be a very useful source of information for the dedicated investigator. An important thing to consider is that any and all information that is ever used can find itself being placed in memory or getting swapped from memory to disk. Furthermore, as noted in chapter 1, it's a geologic process, not something that an intruder or user of the system has any direct control over, let alone knowledge of. This gives us the potential to find information that was thought to be destroyed or otherwise lost. We'll also see in chapter 7 that once on the disk that it's nearly impossible to completely eliminate these mischievous bits, barring physical destruction.
Certain types of data, such as found in log files and file headers, are stored in repetitive and simple formats without a great deal of variety, and simple filters or searches may be one of the most efficient and effective methods for recovering such data.
For example, if you wanted to see all the system log file records (which might start with the month, day, and time) on the disk from the first week of January sorted by date you could use the UNIX strings and grep commands combined with a text pager:
linux # strings /dev/sda1 | egrep \
'^Jan [1-7] [0-9][0-9]:[0-9][0-9]:[0-9][0-9]' | \
sort | less
This would not only display your log files but any deleted data on the disk as well. Since this searches through the entire disk it can be quite slow but it's certainly better than nothing, and more concise regular expressions or programs may be used to further separate the digital wheat from chaff.
Many times, however, you would like to examine or search a part of a system rather than a relatively large subsection of it. TCT's pcat command, which captures the raw memory contained in a process, can be used to find any date strings within the currently running syslogd process:
linux # ps axuww|grep syslog
root 337 0.0 0.0 1156 448 ? S Feb10 15:29 syslogd -m 0 linux
# pcat 337 | strings | egrep '[0-9][0-9]:[0-9][0-9]:[0-9][0-9]' |
egrep 'Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec'
Sat Oct 13 09:57:00 2001 tsunami.trouble.org inetd[187]: \
telnet[17637] from 216.240.49.170 4514
Aug 12 03:08:53 ipmon[135]: 03:08:52.883456 hme0 @0:8 p \
211.78.133.66,655 -> 216.240.49.180,53 PR udp len 20 54 K-S IN
Oct 5 15:03:23 tsunami.trouble.org inetd[187]: telnet[6997] \
from 216.240.49.165 62063
Sep 22 11:55:20 tsunami.trouble.org sendmail[1059]: LAA01057: \
to=zen@fish.com, ctladdr=root (0/1), delay=00:00:01, \
xdelay=00:00:00, mailer=relay, relay=fish.com. [216.240.49.170],\
stat=Sent (Ok: queued as 60101179E6)
[...]
This shows what is currently in the processes' memory - as can be seen here we have log entries spanning several months! While how much and what kind of data is in a running process varies wildly from system to system, process to process, and the activity levels of the computer in question, this can be an invaluable source of information. Here the log entries could be checked against what is in the actual system logs - if the entries in memory are not present in the log file, then something is amiss.
If you're really serious about making sense of data that has no shape or defining boundaries, TCT's Lazarus automatically categorizes data based on the content that it finds, and may be useful in finding not only time-based data but giving form to arbitrary content based on what it looks and smells like to the program.
Some programs keep their time related data in memory but can be coaxed into divulging their secrets in a fairly orderly fashion. For instance Bind, the standard UNIX DNS daemon, is perhaps the most widely relied upon program on the Internet. Almost anytime an email is sent, a web site is visited, music downloaded, etc., Bind is used to translate the name of the server (like "fish.com") to an IP address (such as those in the Barney investigation.)
DNS has several types of records, perhaps the most widely used being PTR (Pointer records, which map an IP number to a host name), A (Address records, which map the computer's name to an IP number), and MX (Mail Exchange records, which tell mail agents where email should be sent to.) Bind maintains an in-memory cache of recent lookup results. On request it can dump this cache in an orderly manner. The request is made via the ndc or rndc command, or by sending a SIGINT signal (e.g. "kill -SIGINT bind-pid").
And while Bind doesn't keep the explicit time for each of the requests, it does display the time the data has left in the cache (this is called its Time To Live, or TTL) before it will discard the data. Listing 2.2 shows a snippet from an rndc dump of the Bind program with this.
$DATE 20040822164741 [...] 165.49.240.10.in-addr.arpa. 479 PTR rainbow.fish.com. 209.in-addr.arpa. 86204 NS chill.example.com. rasta.example.com. 10658 A 192.168.133.11 al.example.com. 86298 NS ns.lds.al.example.com. 4.21.16.10.in-addr.arpa. 86285 PTR mail.example.com. [...]Listing 2.2: A fragment of in-memory dump of a Bind database (version 9), with the respective TTL's in bold.
If you were able to obtain the real TTL value and subtract Bind's time left for a specific request in the cache you will - in theory - know how long ago the query happened. We can look TTLs the Internet for any DNS resource record, using the host command.
linux # host -t soa -v porcupine.org
[...]
porcupine.org 10800 IN SOA spike.porcupine.org wietse.porcupine.org(
2004071501 ;serial (version)
43200 ;refresh period
3600 ;retry refresh this often
1209600 ;expiration period
86400 ;minimum TTL
)
[...]
If you were running your own caching name server it would save the TTL (10800, in this case) and subsequent requests would show the TTL counter decrementing (normally this value should remain the same from query to query.) In order to get a definitive value for a TTL you must ask an authoritative name server and look at the TTL that comes back with it, or, if using your own server ensure that you clear its cache first, as shown in figure 2.2:
<- DNS response TTL count down -> ------+=============+================>X-------> Time -> ^ ^ ^ | | | | | | Initial Bind TTL DNS response Cache dump expiration timeFigure 2.2: How DNS MAC times are generated and collected
Taking the difference between the two TTL values and the time of the Bind cache dump gives you the approximate time of the query (approximate because the original TTL could have changed in the meantime.) To do this effectively we'll need to write a program. One of the big differences between an expert investigator and a good one is the ability to react to new situations. For instance here we'll have to write a small program better understand the situation after a scan. The ability to generate small programs or do back-of-the-envelope analysis on data can be invaluable in an investigation (a classic text on the spirit of writing small tools can be found at [Kernighan, 1976])
We're big fans of scripting languages like awk, Perl, and others. The Perl code in listing 2.3 processes the data base dump results of Bind as shown above and prints out a sorted version of the lookup times in just such a manner. It first consults the local name server's cache to see how much time is left and then looks up the full TTL from a remote name server.
#!/usr/local/bin/perl
use Time::Local;
while (<>) {
if (/^\$DATE/) { $TIME = &parse_date(); }
# look for interesting DNS records
($r, $ttl) = &parse_record_data();
next unless $r;
# get the host's TTL from net
open(HOST, "host -v -t soa $r|") || die "Can't run host\n";
while (<HOST>) {
if (/SOA/) { ($httl = $_) =~ s/^\S+\s+(\d+)\s+.*$/$1/; last; }
}
close(HOST); chop($httl);
# save the difference between the two
if ($httl) {
$t=$TIME-($httl-$ttl);
if ($t < time) {
if (! defined($time{"$t,$type"})) { $time{"$t,$type"} = $r;}
else { $time{"$t,$type"} .= "\n" . " " x 31 . "$r";}
}
}
}
# output the sorted logs
for $_ (sort keys %time) {
($time, $type) = split(/,/, $_);
print localtime($time) . " ($type) " . $time{"$_"} . "\n";
}
Listing 2.3:
A Perl program to print out MACdns records. The full implementation,
which includes the parse_date() and parse_record_data()
functions was omitted to save space; the complete script is available
at the book website.
On most sites DNS is very busy; even on our personal domains we get lots of requests and attacks. We dumped our own Bind cache and ran the program against it, and the times in listing 2.4 show a brief slice of time when someone had taken an interest in us. You might think of this as a sort of MACdns measurement, something that shows you when someone looks at your systems. And just like MACtimes they may not provide much value in isolation, but if additional network activity were spotted after this it could give a clue as to when the first probes were started.
Sun Aug 22 09:56:05 2004 (A) 5.167.54.10.in-addr.arpa.
mail.earthlink.example.com.
230.253.168.192.in-addr.arpa.
Sun Aug 22 09:56:07 2004 (A) 7.32.4.10.in-addr.arpa.
Sun Aug 22 09:56:08 2004 (A) ens2.UNIMELB.example.com.
mx1.hotmail.example.com.
Sun Aug 22 09:56:09 2004 (PTR) 86.90.196.10.in-addr.arpa.
Listing 2.4: A fragment of Bind's processed memory cache.
The A records here are when our SMTP mailer wanted to send mail to another site needed to look up the IP address from the host name. The PTR record was when a computer was probing our ssh daemon, which logged the IP address along with the resolved host name.
With busy DNS domains interesting activity can be hard to spot - but not impossible, or even improbable. And yes, intruders can play games by juggling their DNS server's TTL to fool such a ploy. But many network services automatically look up the name of any connecting system, and once the information is in memory the process must either be killed or have its memory flushed or recycled (perhaps via a restart or simply over time as the program forgets what has happened in the past) to destroy the evidence. This is also made difficult because name servers are often in protected areas of the network. And the mere fact that programs have been restarted or killed is suspicious to the watchful eye. And so the game continues.
While Bind is simply one program - albeit an important one - on a UNIX system, it is not going to solve many problems by itself. This is simply an example of a broader class of programs and opportunities, each with their own ideas on how to implement such things. Time is everywhere, but sometimes you must hunt it down.
Journaling file systems have been a standard feature of enterprise-class systems for a long time, and are also available for popular systems such as Linux and Microsoft Windows. Examples are Ext3fs, JFS, NTFS, Reiserfs, XFS, and others. With a journaling file system, part of all of the disk updates are first written to a journal file before they are committed to the file system itself [Robbins, 2001]. While at first sight this seems like extra work, it can significantly improve the recovery from a system crash. Depending on what optimizations the file system is allowed to make, journaling does not need not to cause loss of performance.
Why does the world need journaling file systems? Every non-trivial file system operation such as creating or appending a file results in a sequence of disk updates that affect both file data (content) and file metadata (the location of file content, and what files belong to a directory). When such a sequence of updates is interrupted due to a system crash, non-journaling file systems such as FFS1, EXT2FS or Windows FAT can leave their file metadata in an inconsistent state. The recovery process involves programs such as fsck or scandisk, and can take several hours with large file systems. Compared to this, recovery with a journaling file system is almost instantaneous: it can be as simple as replaying the "good" portion of the journal to the file system, and discarding the rest.
Footnote 5: FFS versions with soft metadata updates avoid this consistency problem by carefully scheduling their disk updates, so that most of the file system check can be run in the background while the system boots up [McKusick, 2004].
While journaling file systems differ widely in the way they manage their information, conceptually they are very easy to understand. There are two major flavors: those that journal metadata only, and those that journal both data and metadata. In this section we will look only at MACtimes, i.e. metadata, although we are aware that journaled file content has great forensic potential, too.
From a forensics point of view, the journal is a time series of MACtime and other file information. It is literally a time machine by itself. Where normal MACtimes allow us to see only the last read/write operation or status change of a file, journaled MACtimes allow us to see repeated access to the same file. Listing 2.5 shows an example of repeated access that was recovered more than 24 hours after the fact from an Ext3fs file system.
time size MAC permissions owner file name 19:30:00 541096 .a. -rwxr-xr-x root /bin/bash 19:30:00 26152 .a. -rwxr-xr-x root /bin/date 19:30:00 4 .a. lrwxrwxrwx root /bin/sh -> bash 19:30:00 550 .a. -rw-r--r-- root /etc/group 19:30:00 1267 .a. -rw-r--r-- root /etc/localtime 19:30:00 117 .a. -rw-r--r-- root /etc/mtab 19:30:00 274 .a. -rwxr-xr-x root /usr/lib/sa/sa1 19:30:00 19880 .a. -rwxr-xr-x root /usr/lib/sa/sadc 19:30:00 29238 m.c -rw------- root /var/log/cron 19:30:00 114453 mac -rw-r--r-- root /var/log/sa/sa19 19:40:00 541096 .a. -rwxr-xr-x root /bin/bash 19:40:00 26152 .a. -rwxr-xr-x root /bin/date 19:40:00 4 .a. lrwxrwxrwx root /bin/sh -> bash 19:40:00 550 .a. -rw-r--r-- root /etc/group 19:40:00 1267 .a. -rw-r--r-- root /etc/localtime 19:40:00 117 .a. -rw-r--r-- root /etc/mtab 19:40:00 274 .a. -rwxr-xr-x root /usr/lib/sa/sa1 19:40:00 19880 .a. -rwxr-xr-x root /usr/lib/sa/sadc 19:40:00 29310 m.c -rw------- root /var/log/cron 19:40:00 115421 mac -rw-r--r-- root /var/log/sa/sa19Listing 2.5: Journaled MACtimes showing repeating activity, recovered more than 24 hours after the fact from an Ext3fs file system journal. For the sake of clarity, dynamically linked libraries were omitted. Files with the same time stamp are sorted alphabetically.
Regular system activity can act as a heartbeat, showing up in logs and in other locations such as the file system journal. Here it turns out that cron, the scheduler for unattended command execution, is running a maintenance program every 10 minutes. Besides the information that we have learned to expect from normal MACtimes, the MACtimes from the journal also reveal how logfiles grow over time, as shown by the file sizes of /var/log/cron and /var/log/sa/sa19.
Rather than exhaustively trying to cover the major journaling file system players, we'll take a short look at the Ext3fs implementation. Ext3fs is particular easy to use because of its compatibility with its predecessor Ext2fs, and has become the default file system with many Linux distributions. Although Ext3fs stores the journal in a regular file, that file is usually not referenced by any directory, and therefore it cannot be accessed by name. The Linux tune2fs command reveals where the journal is kept:
linux# tune2fs -l /dev/hda1 | grep -i journal Filesystem features: has_journal filetype needs_recovery sparse_super Journal UUID: <none> Journal inode: 8 Journal device: 0x0000
This shows, among others, that the journal is stored as a regular file with inode number 8 (see Chapter 3 for an introduction to inodes and more). What it does not show is that the journal has a fixed size of 32 MBytes. As part of an investigation it is therefore worthwhile to save the content of the journal with the TCT's icat command early, before its contents are overwritten with newer information. However, be sure to save it to a different file system, otherwise the journal may end up destroying itself with its own content.
linux# icat /dev/hda1 8 >journalfile
The Linux debugfs file system debugger may be used to examine the file system journal in some detail. The following command dumps recent access times for the /etc/passwd file:
linux# debugfs -R 'logdump -c -i /etc/passwd' /dev/hda1 | grep atime
atime: 0x4124b4b8 -- Thu Aug 19 07:10:00 2004
atime: 0x4124b5e4 -- Thu Aug 19 07:15:00 2004
atime: 0x4124b710 -- Thu Aug 19 07:20:00 2004
. . .
In order to examine a saved journal file, we would specify "-f journalfile" on the logdump command line.
The standard debugfs command is sufficient if we want to look at only one file at a time, and if we already know what file we are looking for. However, in order to produce multi-file reports like the one in figure 2.7 we had to use a modified version that allows us to see all the MACtime information in the journal. This software is available via the book website.
As with all tools that are used for unintended purposes, debugfs can produce unexpected results at times. The version that we used (1.35) did not always recognize where the journal terminates, and thus it would mis-interpret the remainder of the journal file. Some judgment is needed when interpreting the results.
The amount of MACtime history that can be recovered from a file system journal depends on the type and amount of activity in the file system, as well as file system implementation details. With file systems such as Ext3fs that journal both data and metadata, the amount of recoverable MACtimes can be disappointingly small. On the other hand, systems with little activity can have records that go back by as much as an entire day or more. In such cases, watching a file system journal can be like watching a tree grow one ring at a time.
A man with a watch knows what time it is. A man with two watches is never sure.
- Segal's Law
By now, the reader might be led to believe that time line reconstruction is only a simple matter of collecting, sorting, and neatly printing information. However, there are many potential problems along the way.
To start with let's consider how we represent time. Usually when thinking of time we think of hours and minutes and seconds, or, perhaps, in a more calendicral sense, something with days, weeks, months, and years included as well. Time zones are another consideration, as are leap years (some years February 29th is a valid date and other times not.) And unfortunately there is no single way used in computing systems or in real life to represent time - even recognizing some formats as representing a time value can be a challenge, let alone converting it to a universal format.
Were these the only problem. Another trio of chronological gremlins are accuracy, drift, and synchronization. No real-world clocks keep perfect time (as defined by various agencies around the world) and there is always an opportunity for errors in records. Uncorrected, computers are notoriously poor time keeping devices, and will usually lose seconds, if not minutes or more each day. After all, no one will spend more money on a computer that has a particularly accurate clock - instead they'll simply buy a good clock! This isn't a large issue to most users, but when dealing with an investigation it can become a large complication, especially if working with multiple computers. The Network Time Protocol ([NTP, 2004]) and other time synchronization efforts can certainly help with this, but will not solve all problems. We'll dodge many of these issues in this book because we're mostly writing about data coming from a single system, but in real investigations there are often many computers involved, and it will often be an issue, especially when the computers in question are out of your control and you can't tell how the systems in question have been maintained.
Systems that act as a central repository for logs often will get log messages from systems in other time zones - yet log the activity in the local time zone. And when computers physically move to another time zone, clocks go bad, intruders attempt to inject false or spurious times into your logging mechanisms, systems lose power, backup clock batteries lose power, etc., it almost ensures a hair-pulling experience.
And none of this addresses the malleability of digital evidence. Simply because a file or record reports a given time doesn't mean it hasn't been changed, nor does a clock that is accurate now mean that it hadn't been incorrect in the past.
Perhaps no other form of data is more interesting, frustrating, relied upon and untrustworthy than time. Provably accurate or consistent time can be extraordinarily difficult to obtain, and should generally only be relied upon when several events or points of view are correlated.
Systems generate a wealth of data about all kinds of activity, and as we cast our information retrieval net wider and wider it becomes easier to catch anomalies or problems. Some forms of time data recovery and processing are difficult to automate and impractical for general use - the system will often only give its secrets out under duress or brute force. Additional work has to be done investigating, documenting, and providing methods to collect such data.
Since computers use time for almost all their actions and decision making processes, perhaps it shouldn't have come as a surprise to see it permeate the system so completely. It was enlightening to us, however, to see first-hand not only some of the different locations (and the near-random success that one has in finding it) that time is kept in but also how redundant the data can be. With time data being so valuable to understanding and reconstructing the past as well as a golden opportunity to detect modified or deleted records, great care and effort should be taken to try and uncover the gems of time scattered through the system.
[Argus, 2004] The Argus web site:
http://www.qosient.com/argus/
[Coffman, 2002] K. G. Coffman and A. M. Odlyzko 'Internet growth: Is there a "Moore's Law" for data traffic?' in: "Handbook of Massive Data Sets," J. Abello, P. M. Pardalos, and M. G. C. Resende, eds., Kluwer, 2002, pp. 47-93.
[Kernighan, 1976] B. W. Kernighan and P. J. Plauger, Software Tools, Addison-Wesley, Reading Mass., 1976.
[McKusick, 2004] Marshall Kirk McKusick, George V. Neville-Neil, "The Design and Implementation of the FreeBSD Operating System", Pearson Education, 2004.
[MSDN, 2004] System Structures;
Kernel-Mode Driver Architecture: Windows DDK.
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/kmarch/hh/kmarch/k112_3de98e8c-d842-45e9-a9bd-948276ef1b87.xml.asp
[NTP, 2004] The official NTP web site:
http://www.ntp.org
[Perl, 2004] Perl's main web site:
http://www.perl.com
[Ptacek, 1998] T. Ptacek and T. Newsham, "Insertion, Evasion, and Denial of Service: Eluding Network Intrusion Detection,", Secure Networks, Inc., January 1998.
[Robbins, 2001] Daniel Robbins, "Advanced filesystem implementor's
guide", developerWorks, June, 2001.
http://www.ibm.com/developerworks/library/l-fs.html
[WIKI, 2004] Many books and web sites talk about the
library of Alexandria and Ptolemy III. As of this writing
the Wikipedia has a particularly good description:
http://en.wikipedia.org/wiki/Library_of_Alexandria